Cache in der Spark UI inspizieren
Ein DataFrame partitioned_df ist vorhanden. Daraus wird eine temporäre Tabelle namens text registriert. text wird anschließend mit spark.catalog.cacheTable('text') gecacht. Wenn du Spark lokal ausführst, ist die Spark UI unter http://localhost:4040/storage/ erreichbar. Für diese Übung sieh dir das folgende Bild an. Es zeigt, was die Spark UI anzeigt, sobald der Cache für text geladen ist:
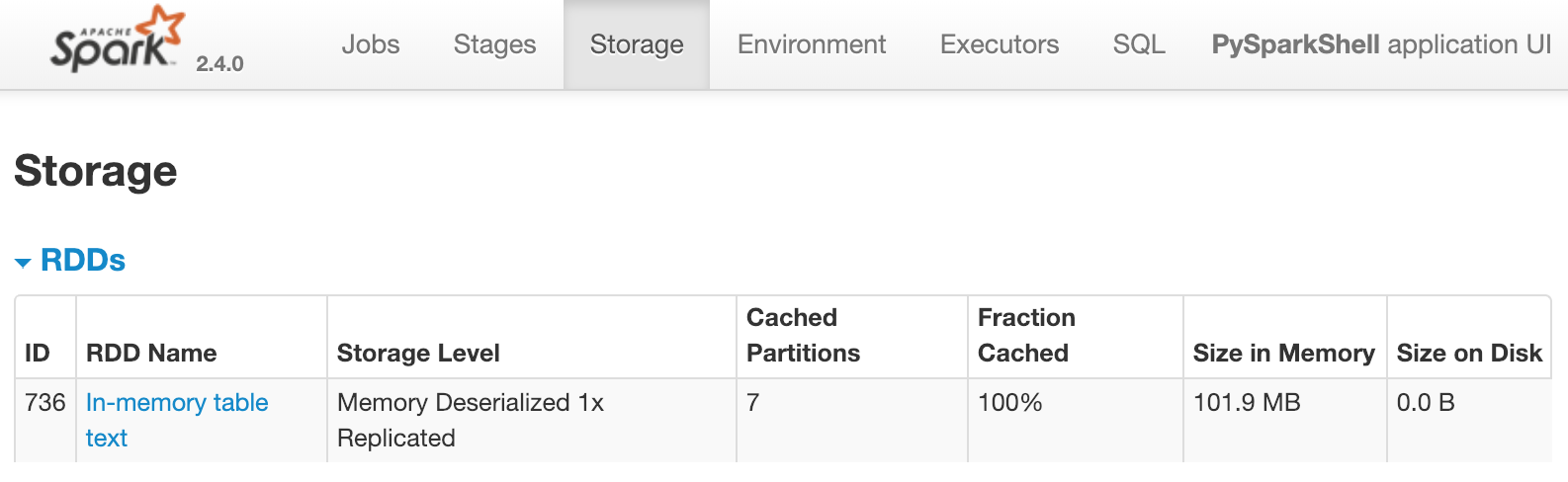
Das Bild zeigt, dass eine Tabelle namens text mit sieben Partitionen im Speicher gecacht ist. Was davon würde sofort dazu führen, dass die oben gezeigte Ansicht in der Spark UI erscheint?
Eine Transformation auf dem zugrunde liegenden DataFrame ausführen, z. B.
df = partitioned_df.distinct().Den zugrunde liegenden DataFrame zählen, z. B.:
partitioned_df.count()Die Tabelle abfragen, z. B.:
spark.sql("select count(*) from text")Abfragen und das Ergebnis anzeigen, z. B.:
spark.sql("select count(*) from text").show()
Diese Übung ist Teil des Kurses
<Kurs>Einführung in Spark SQL mit Python</Kurs>Interaktive praktische Übung
Verwandle Theorie mit einer unserer interaktiven Übungen in die Praxis
 Übung starten
Übung starten