Umgang mit Label-Rauschen
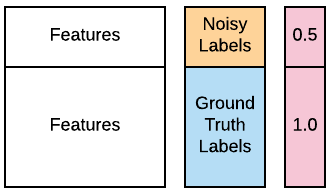
Eine deiner Cyberanalystinnen teilt dir mit, dass viele Labels für die ersten 100 Quellrechner in deinen Trainingsdaten aufgrund eines Datenbankfehlers falsch sein könnten. Sie hofft, dass du die Daten trotzdem nutzen kannst, weil die meisten Labels noch korrekt sind, bittet dich aber, diese 100 Labels als „rauschbehaftet“ zu behandeln. Zum Glück weißt du, wie das geht – mit gewichtetem Lernen. Die verunreinigten Daten liegen in deinem Workspace als X_train, X_test, y_train_noisy, y_test vor. Du möchtest prüfen, ob du die Leistung eines GaussianNB()-Klassifikators mit gewichtetem Lernen verbessern kannst. Du kannst den optionalen Parameter sample_weight verwenden, der von den .fit()-Methoden der meisten gängigen Klassifikatoren unterstützt wird. Die Funktion accuracy_score() ist vorab geladen. Zur Orientierung kannst du das folgende Bild heranziehen.
Diese Übung ist Teil des Kurses
<Kurs>Machine-Learning-Workflows in Python entwerfen</Kurs>Übungsanweisungen
- Fitte eine Instanz von
GaussianNB()auf die Trainingsdaten mit den verunreinigten Labels. - Berichte die Genauigkeit auf den Testdaten mit
accuracy_score(). - Erstelle Gewichte, die Ground-Truth-Labels doppelt so hoch gewichten wie rauschbehaftete Labels. Denk daran: Die Gewichte beziehen sich auf die Trainingsdaten.
- Fitte den Klassifikator mit den oben genannten Gewichten erneut und berichte die Genauigkeit.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))