Training the word embedding based model
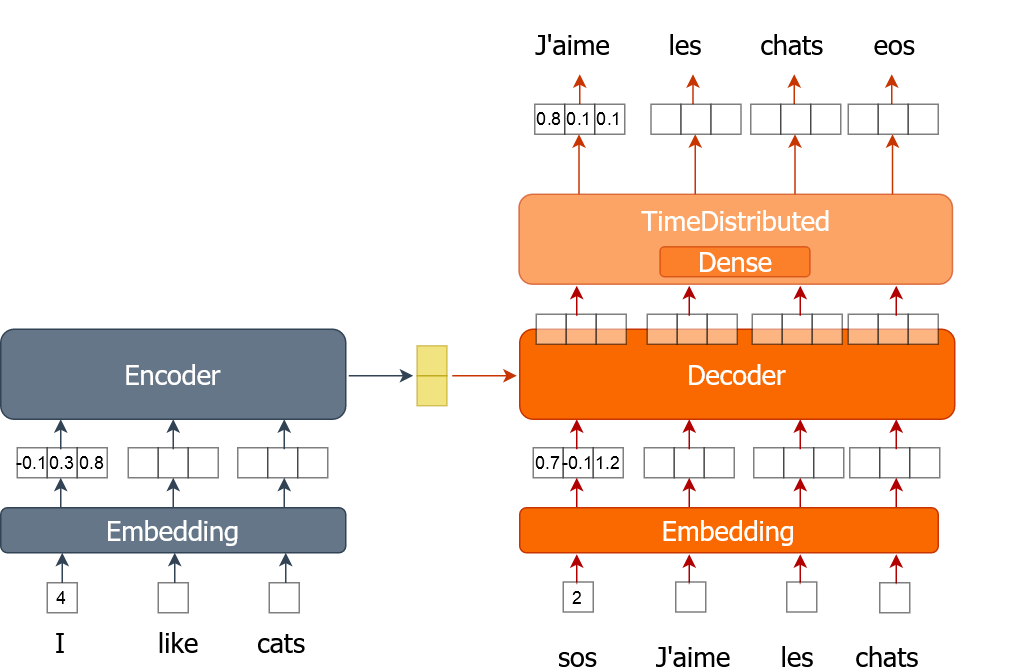
Here you will learn how to implement the training process for a machine translator model that uses word embeddings. A word is represented as a single number instead of a one-hot encoded vector as you did in previous exercises. You will train the model for multiple epochs while traversing through the full dataset in batches.
For this exercise you are provided with training data (tr_en and tr_fr) in the form of a list of sentences. You will only use a very small sample (1000 sentences) of the actual data as it can otherwise take very long to train. You also have the sents2seqs() function and the model, nmt_emb, that you implemented in the previous exercise. Remember that we use en_x to refer to encoder inputs and de_x to refer to decoder inputs.
This exercise is part of the course
Machine Translation with Keras
Exercise instructions
- Get a single batch of French sentences without onehot encoding using the
sents2seqs()function. - Get all the words except the last from
de_xy. - Get all the words except the first from
de_xy_oh(French words with onehot encoding). - Train the model using a single batch of data
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))