Fit a decision tree
Random forests are a go-to model for predictions; they work well out of the box. But we'll first learn the building block of random forests -- decision trees.
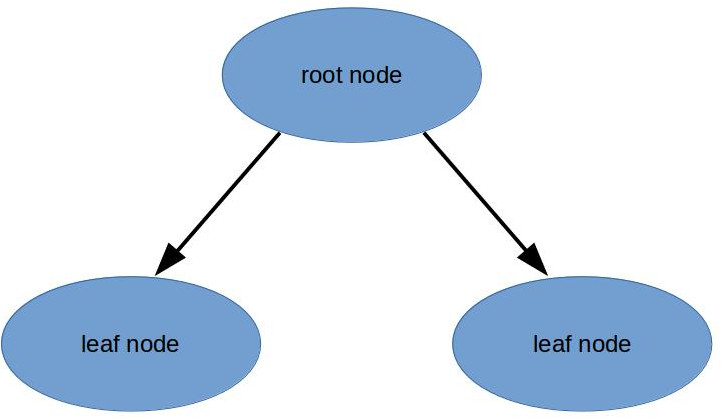
Decision trees split the data into groups based on the features. Decision trees start with a root node, and split the data down until we reach leaf nodes.
We can use sklearn to fit a decision tree with DecisionTreeRegressor and .fit(features, targets).
Without limiting the tree's depth (or height), it will keep splitting the data until each leaf has 1 sample in it, which is the epitome of overfitting. We'll learn more about overfitting in the coming chapters.
This exercise is part of the course
Machine Learning for Finance in Python
Exercise instructions
- Use the imported class
DecisionTreeRegressorwith default arguments (i.e. no arguments) to create a decision tree model calleddecision_tree. - Fit the model using
train_featuresandtrain_targetswhich we've created earlier (and now contain day-of-week and volume features). - Print the score on the training features and targets, as well as
test_featuresandtest_targets.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
from sklearn.tree import DecisionTreeRegressor
# Create a decision tree regression model with default arguments
decision_tree = ____
# Fit the model to the training features and targets
decision_tree.fit(____)
# Check the score on train and test
print(decision_tree.score(train_features, train_targets))
print(decision_tree.score(____))