The database schema
By now, you know that SQL databases always have a database schema. In the video on databases, you saw the following diagram:
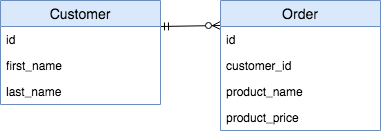
A PostgreSQL database is set up in your local environment, which contains this database schema. It's been filled with some example data. You can use pandas to query the database using the read_sql() function. You'll have to pass it a database engine, which has been defined for you and is called db_engine.
The pandas package imported as pd will store the query result into a DataFrame object, so you can use any DataFrame functionality on it after fetching the results from the database.
This exercise is part of the course
Introduction to Data Engineering
Exercise instructions
- Complete the
SELECTstatement so it selects thefirst_nameand thelast_namein the"Customer"table. Make sure to order by the last name first and the first name second. - Use the
.head()method to show the first3rows ofdata. - Use
.info()to show some general information aboutdata.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Complete the SELECT statement
data = pd.read_sql("""
SELECT first_name, ____ FROM "____"
ORDER BY ____, ____
""", db_engine)
# Show the first 3 rows of the DataFrame
print(data.head(____))
# Show the info of the DataFrame
print(data.____())