Data pipeline steps
One of your more business-critical data pipelines at Sierra Publishing relies on a high-velocity data stream, which comes from a Kafka data stream. We need to read in the data and join it with a few other datasets.
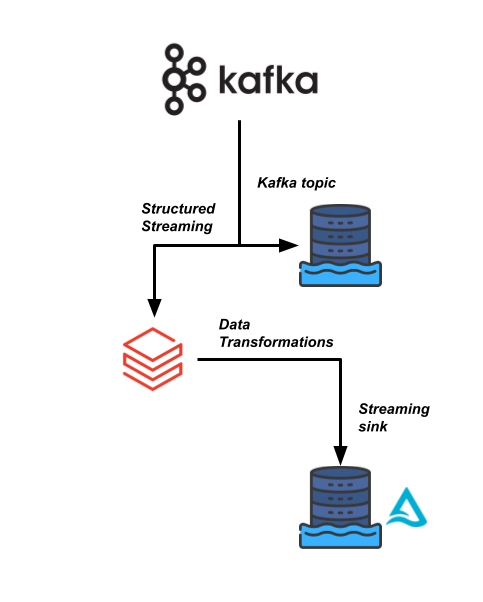
Your data engineering team would like to use Databricks to make this data pipeline more efficient and allow the downstream consumers to read this data in real time for their analytics.
This exercise is part of the course
Databricks Concepts
Hands-on interactive exercise
Turn theory into action with one of our interactive exercises
 Start Exercise
Start Exercise