Algoritmo de regressão logística
Vamos explorar os bastidores e implementar um algoritmo de regressão logística. Como a função glm() do R é bem complexa, você vai se limitar a implementar uma regressão logística simples para um único conjunto de dados.
Em vez de usar soma dos quadrados como métrica, vamos usar verossimilhança. No entanto, a log-verossimilhança é mais estável computacionalmente, então usaremos ela. Na verdade, há mais uma mudança: como queremos maximizar a log-verossimilhança, mas optim() por padrão busca valores mínimos, é mais fácil calcular a log-verossimilhança negativa.
O valor da log-verossimilhança para cada observação é
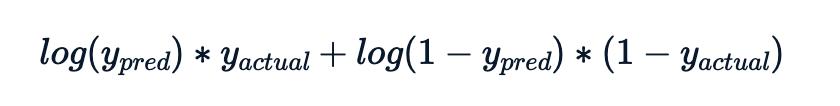
A métrica a calcular é menos a soma dessas contribuições de log-verossimilhança.
Os valores explicativos (a coluna time_since_last_purchase de churn) estão disponíveis como x_actual.
Os valores de resposta (a coluna has_churned de churn) estão disponíveis como y_actual.
Este exercicio faz parte do curso
Regressão intermediária no R
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Set the intercept to 1
intercept <- ___
# Set the slope to 0.5
slope <- ___
# Calculate the predicted y values
y_pred <- ___
# Calculate the log-likelihood for each term
log_likelihoods <- ___
# Calculate minus the sum of the log-likelihoods for each term
___