Desempenho do portfólio com gradient boosting
Até aqui, você viu como prever a probabilidade de inadimplência usando LogisticRegression() e XGBClassifier(). Você analisou algumas métricas e viu amostras das previsões, mas qual é o efeito geral no desempenho do portfólio? Use a perda esperada como um cenário para mostrar a importância de testar modelos diferentes.
Um data frame chamado portfolio foi criado para reunir as probabilidades de inadimplência dos dois modelos, a perda dado o default (assuma 20% por enquanto) e o loan_amnt, que será considerado como a exposição no default.
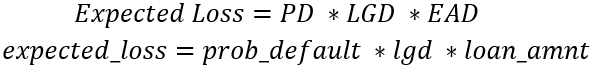
O data frame cr_loan_prep, junto com os conjuntos de treino X_train e y_train, já foram carregados no workspace.
Este exercicio faz parte do curso
Modelagem de Risco de Crédito em Python
Instruções do exercicio
- Imprima as cinco primeiras linhas de
portfolio. - Crie a coluna
expected_losspara os modelosgbtelr, nomeadasgbt_expected_losselr_expected_loss. - Imprima a soma de
lr_expected_losspara todo oportfolio. - Imprima a soma de
gbt_expected_losspara todo oportfolio.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Print the first five rows of the portfolio data frame
print(____.____())
# Create expected loss columns for each model using the formula
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
# Print the sum of the expected loss for lr
print('LR expected loss: ', np.____(____[____]))
# Print the sum of the expected loss for gbt
print('GBT expected loss: ', np.____(____[____]))