Zufällige Testdatensätze erstellen
Bevor du ein anspruchsvolleres Kreditvergabemodell erstellst, ist es wichtig, einen Teil der Kreditdaten zurückzuhalten, um zu simulieren, wie gut es die Ergebnisse zukünftiger Kreditanträge vorhersagt.
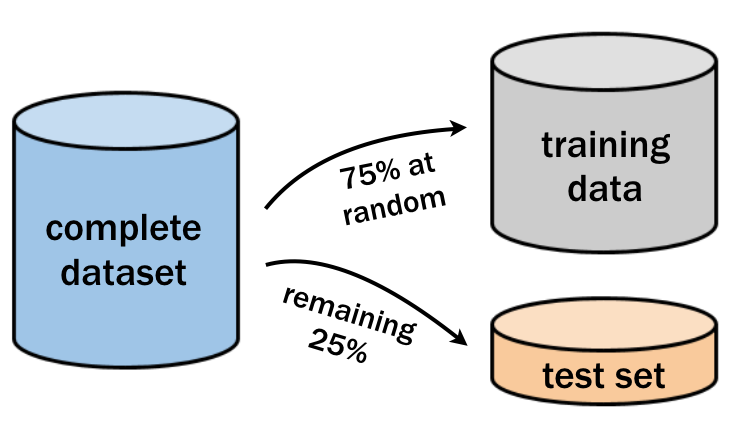
Wie in der folgenden Grafik dargestellt, kannst du 75 % der Beobachtungen für das Training und 25 % für das Testen des Modells verwenden.
Mit der Funktion sample() kannst du eine Zufallsstichprobe von Zeilen erzeugen, die in den Trainingssatz aufgenommen werden. Übergebe ihr einfach die Gesamtzahl der Beobachtungen und die für das Training benötigte Anzahl.
Verwende den resultierenden Vektor von Zeilen-IDs, um die Kredite in Trainings- und Testdatensätze zu unterteilen. Der Datensatz loans steht dir zur Verfügung.
Diese Übung ist Teil des Kurses
<Kurs>Überwachtes Lernen in R: Klassifikation</Kurs>Übungsanweisungen
- Wende die Funktion
nrow()an, um zu bestimmen, wie viele Beobachtungen im Datensatzloansenthalten sind, und wie viele du für eine 75-%-Stichprobe benötigst. - Verwende die Funktion
sample(), um einen Integer-Vektor von Zeilen-IDs für die 75-%-Stichprobe zu erstellen. Das erste Argument vonsample()sollte die Anzahl der Zeilen im Datensatz sein, das zweite die Anzahl der Zeilen, die du in deinem Trainingssatz brauchst. - Unterteile die Daten
loansmithilfe der Zeilen-IDs, um den Trainingsdatensatz zu erstellen. Speichere ihn alsloans_train. - Unterteile
loanserneut, wähle dieses Mal jedoch alle Zeilen aus, die nicht insample_rowsenthalten sind. Speichere dies alsloans_test
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Determine the number of rows for training
# Create a random sample of row IDs
sample_rows <- sample(___, ___)
# Create the training dataset
loans_train <- loans[___]
# Create the test dataset
loans_test <- loans[___]