Probabilistic Relational Neighbor Classifier
In this exercise, you will apply the probabilistic relational neighbor classifier to infer churn probabilities based on the prior churn probability of the other nodes.
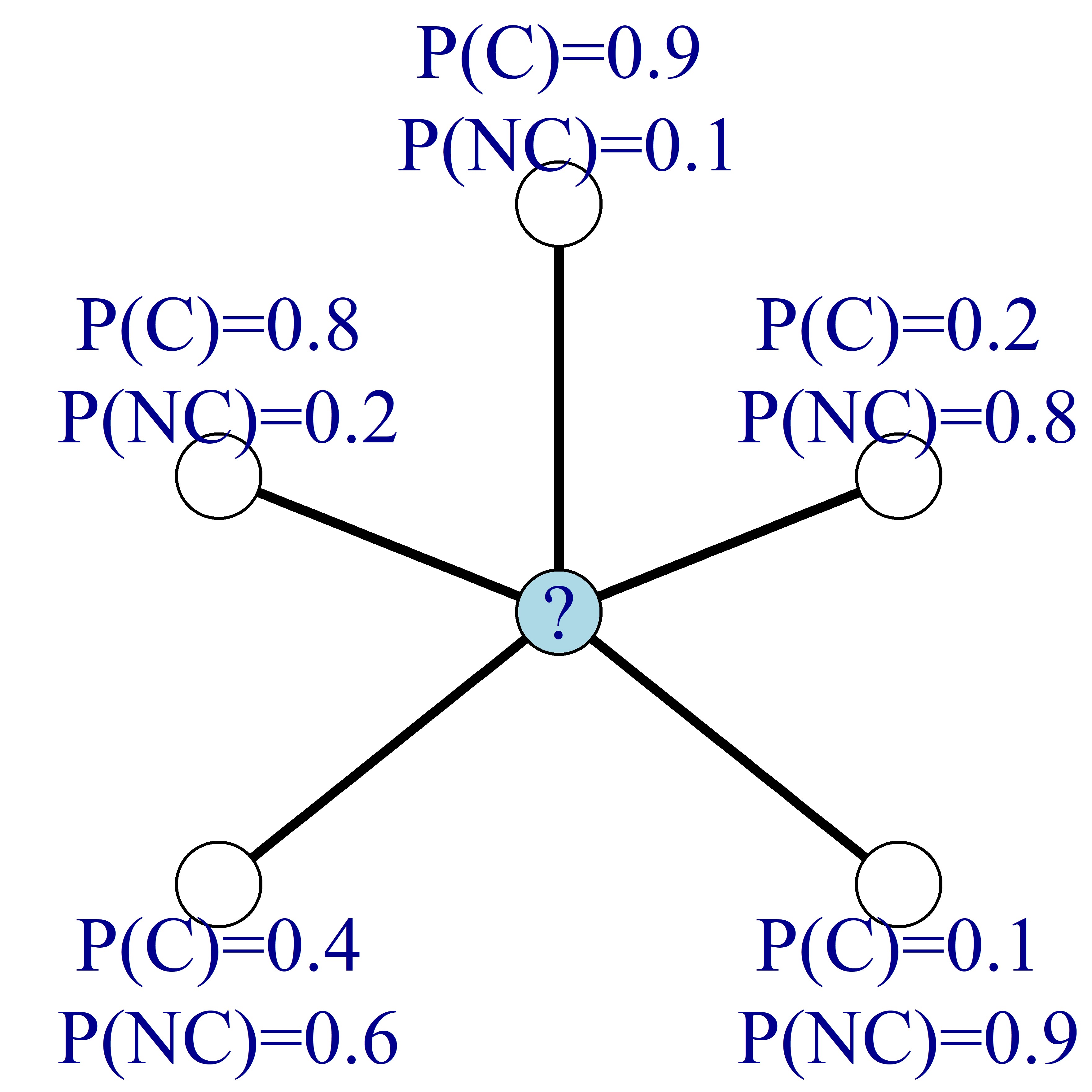
Instead of knowing the nodes' labels, suppose you know each node's probability of churn, as in the image below. In the image, C stands for churn and NC for non-churn.
Then, as before, you can update the churn probability of the nodes by finding the average of the neighboring nodes' churn probabilities.
This exercise is part of the course
Predictive Analytics using Networked Data in R
Exercise instructions
- Find the churn probability of the 44th customer in the vector
churnProb. - Update the churn probability by multiplying
AdjacencyMatrixbychurnProband dividing with the vectorneighborswhich contains the neighborhoods' sizes. We have addedas.vector()around the matrix operations. Assign the result tochurnProb_updated. - Find the updated churn probability of the 44th customer in the vector
churnProb_updated. - What happened to the churn probability of the 44th customer?.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Find churn probability of the 44th customer
churnProb[___]
# Update the churn probabilties and the non-churn probabilities
churnProb_updated <- as.vector((AdjacencyMatrix %*% ___) / ___)
# Find updated churn probability of the 44th customer
churnProb_updated[___]