Data encoding
Encoding of categorical data makes them useful for machine learning algorithms. R encodes factors internally, but encoding is necessary for the development of your own models.
In this exercise, you'll first build a linear model using lm() and then develop your own model step-by-step.
In one hot encoding, a separate column is created for each of the levels.
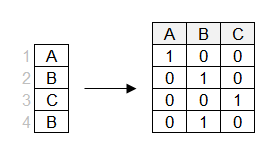
Note that one of the columns can be derived based on the others (e.g. 0's in the columns "B" and "C" imply 1 in the "A" column). So, you can drop the first column for the linear regression. We will review linear models in more detail in the next chapter.
For one hot encoding, you can use dummyVars() from the caret package.
To use it, first create the encoder and then transform the dataset:
encoder <- dummyVars(~ category, data = df)
predict(encoder, newdata = df)
The complete cases of the survey dataset from the MASS package are available as survey.
The caret package has been preloaded.
This exercise is part of the course
Practicing Statistics Interview Questions in R
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Fit a linear model
lm(___ ~ Exer, data = ___)