Confusion matrix
Using scikit-learn's confusion_matrix() function, you can easily create your classifier's confusion matrix and gain a more nuanced understanding of its performance. It takes in two arguments: The actual labels of your test set - y_test - and your predicted labels.
The predicted labels of your Random Forest classifier from the previous exercise are stored in y_pred and were computed as follows:
y_pred = clf.predict(X_test)
Important note: sklearn, by default, computes the confusion matrix as follows:
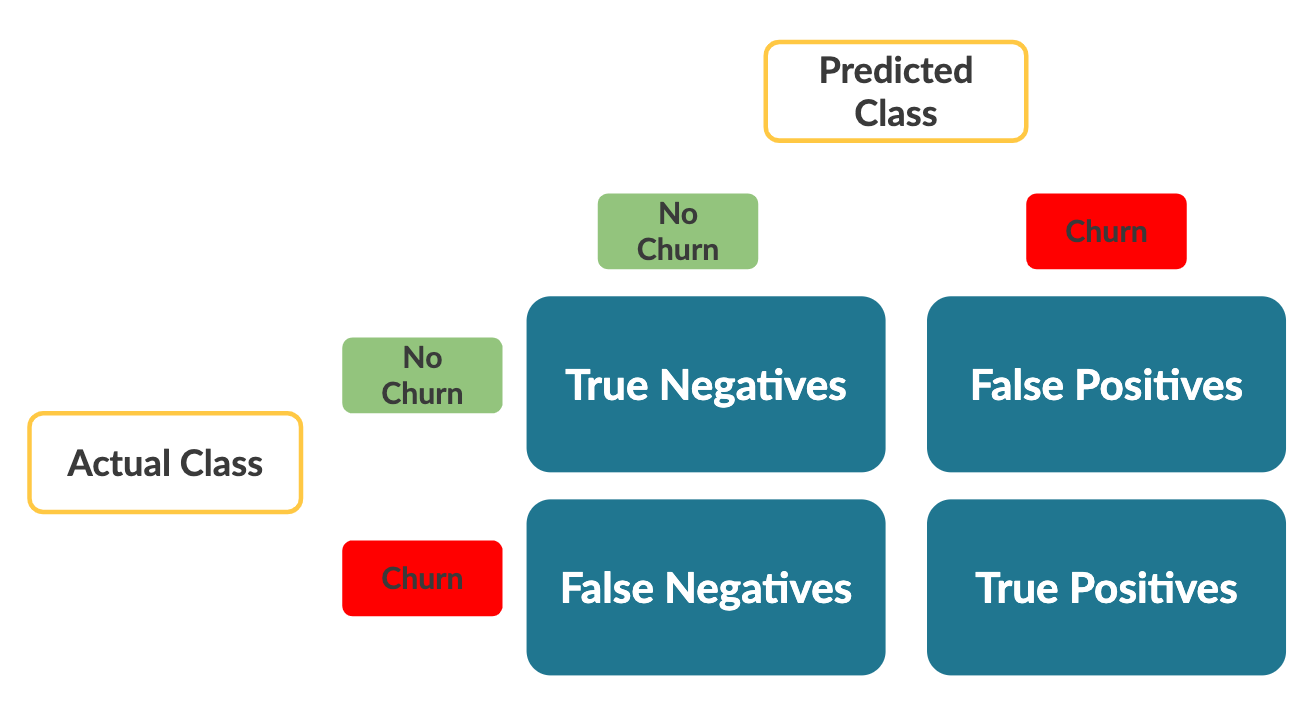
Notice that the axes are the opposite of what you saw in the video. The metrics themselves remain the same, but keep this in mind when interpreting the table.
This exercise is part of the course
Marketing Analytics: Predicting Customer Churn in Python
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Import confusion_matrix