Dealing with label noise
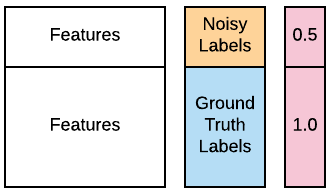
One of your cyber analysts informs you that many of the labels for the first 100 source computers in your training data might be wrong because of a database error. She hopes you can still use the data because most of the labels are still correct, but asks you to treat these 100 labels as "noisy". Thankfully you know how to do that, using weighted learning. The contaminated data is available in your workspace as X_train, X_test, y_train_noisy, y_test. You want to see if you can improve the performance of a GaussianNB() classifier using weighted learning. You can use the optional parameter sample_weight, which is supported by the .fit() methods of most popular classifiers. The function accuracy_score() is preloaded. You can consult the image below for guidance.
This exercise is part of the course
Designing Machine Learning Workflows in Python
Exercise instructions
- Fit an instance of
GaussianNB()to the training data with the contaminated labels. - Report its accuracy on the test data using
accuracy_score(). - Create weights that assign twice as much weight to ground truth labels than to noisy labels. Remember that the weights concern the training data.
- Refit the classifier using the above weights and report its accuracy.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))